Want to know the best healthcare data warehouse for your organization? You’ll need to start first by modeling the data, because the data model used to build your healthcare enterprise data warehouse (EDW) will have a significant effect on both the time-to-value and the adaptability of your system going forward. Each of the models I describe below bind data at different times in the design process, some earlier, some later.
As you’ll see, we believe that binding data later is better. The three approaches are 1) the enterprise data model, 2) the independent data model, and 3) the Health Catalyst Late-Binding™ approach.

Building the best enterprise data warehouse (EDW) for your health system starts with modeling the data. Why? Because the data model used to build your EDW has a significant impact on both the time-to-value and adaptability of your system going forward. This article outlines the strengths and weaknesses of the two most common relational data models, and compares them to the Health Catalyst® Late-Binding™ approach.
“Binding” data refers to the process of mapping data aggregated from source systems to standardized vocabularies (e.g., SNOMED and RxNorm) and business rules (e.g., length of stay definitions and ADT rules) in the EDW. In other words, it means optimizing data from all these different sources so it can be used together for analysis. Binding data this way is required in any relational database model.
Each of the models described in this article bind data at different times in the design process: some earlier, some later. Health Catalyst believes that a methodology of binding data at the right time is the right approach (sometimes early, sometimes late, and sometimes in between). Adopting a methodology that restricts your flexibility in binding early or late limits your ability to be successful with your analytic efforts.
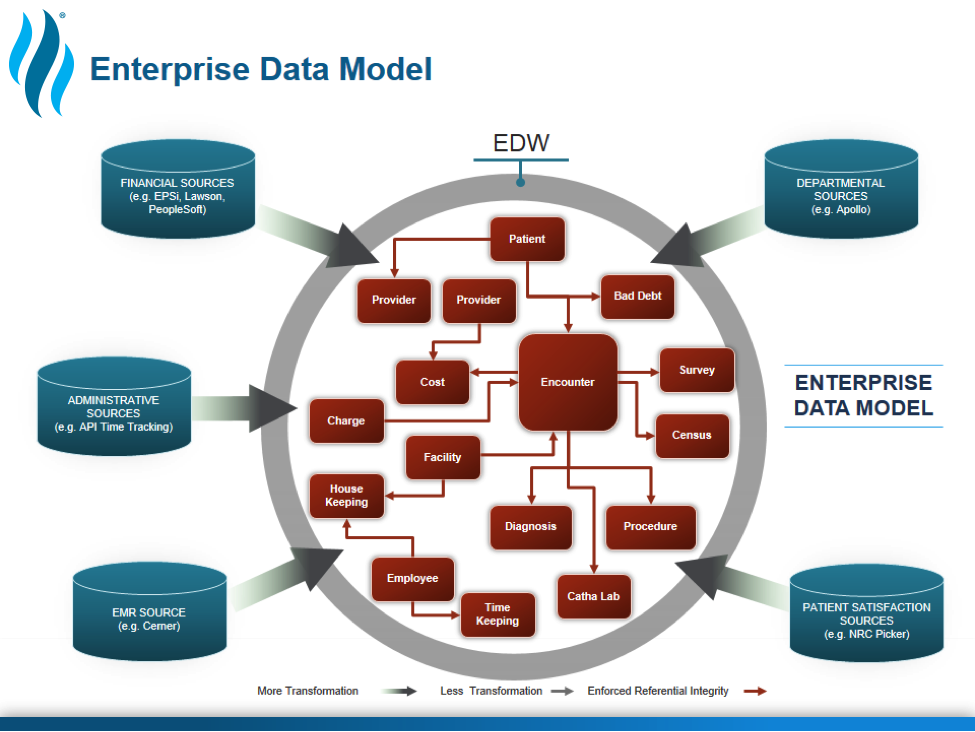
The enterprise data model approach (Figure 1) to data warehouse design is a top-down approach that most analytics vendors advocate for today. The goal of this approach is modeling the perfect database from the start—determining, in advance, everything you’d like to be able to analyze to improve outcomes, safety, and patient satisfaction, and then structuring the database accordingly.
In theory, if you’re building a new system in a vacuum from the ground up, the enterprise data model approach is the best choice. In the reality of healthcare, however, you’re not building a net-new system when you implement an EDW; You’re building a secondary system that receives data from systems that have already been deployed. Extracting data from existing systems and making it all play well together in a net-new system is like trying to turn an apple into a banana. With patience, the right skills, and a bit of magic, it’s possible, but it is also incredibly time-consuming and expensive.
In all my years in the healthcare analytics space, I’ve never seen a project that uses this approach bear much fruit until well after two years of effort. This delayed time-to-value is a significant downside of this model. Binding the data and defining every possible business rule in advance takes a lot of time. There are two additional drawbacks of this approach:
Many data warehousing initiatives based on this enterprise data model approach end up failing.
The independent data mart approach to data warehouse design is a bottom-up approach in which you start small, building individual data marts as you need them. If you want to analyze revenue cycle or oncology, you build a separate data mart for each, bringing in data from the handful of source systems that apply to that area.
The benefit of this approach is that you can start implementing and measuring much quicker—a big difference from the two- to five-year lifecycle of the enterprise data model approach. However, there are three major drawbacks of this model:
The video below highlights the problems with this model. Using a grocery shopping analogy, let’s say you’re baking cookies. The recipe indicates that you’ll need four eggs, two cups of shortening, etc. You go to the store and buy exactly what you need, pulling four eggs out of the carton, opening containers of shortening and measuring it with your measuring cup, etc. This is efficient now, but later, when you need to bake a cake, back to the grocery store you go to get three cups of flour. You get the idea.
Figure 2: Independent data mart approach explained
Health Catalyst advocates for a late-binding approach to data modeling that overcomes the challenges inherent in the first two models. The adaptive, pragmatic late-binding approach is designed to handle the rapidly changing business rules and vocabularies that characterize healthcare. Here is a high-level description of Health Catalyst’s Late-Binding™ approach:
In the raw data zone, data is moved in its native format without transformation or binding to any business rules. Typically, the only organization or structure added in this layer is outlining what data came from what source system—Health Catalyst calls these areas source marts. Although all data starts in the raw data zone, it’s too vast of a landscape for less technical users. Typical users include ETL developers, data stewards, data analysts, and data scientists, who are defined by their ability to derive new knowledge and insights amid vast amounts of data. This user base tends to be small and spends a lot of time sifting through data, then pushing it into other zones.
Source data is ingested into the EDW, then used to build shared data marts in the trusted data zone. Terminology is standardized at this point (e.g., RxNorm, SNOMED, etc.). The trusted data zone holds data that serves as universal truth across the organization. A broader group of people has applied extensive governance to this data, which has more comprehensive definitions that the entire organization can stand behind. Trusted data could include building blocks, such as the number of ED visits in a certain period, inpatient admission rates from one year to the next, or the number of members in risk-based contracts.
Meaning is applied to raw data so it can be integrated into a common format and used by specific lines of business. Data in the refined data zone is grouped into Subject Area Marts (SAMs, often referred to as data marts). A department manager looking for end-of-month numbers would query a SAM rather than the EDW. SAMs become the source of truth for specific domains. They take subsets of data from the larger pool and add value that’s meaningful to a finance, clinical, operations, supply chain, or other administrative area.
Refined data is used by a broad group of people, but is not yet blessed by everyone in the organization. In other words, people beyond specific subject areas may not be able to derive meaning from refined data. A SAM gets promoted to the trusted data zone when the definitions applied to its data elements have broadened to a much larger group of people.
Anyone can decide to move data from the raw, trusted, or refined data zones into the exploration zone. Here, data from all these zones can be morphed for private use. Once information has been vetted, it is promoted for broader use in the refined data zone.
The late-binding approach is something like just-in-time data binding. Rather than trying to perfect a data model up front, when you can only guess what all the use cases for the data will be, you bind the data at the right time in the process to solve an actual clinical or business problem (or when there is general agreement on a given clinical or business concept).
You don’t have to make final decisions about your data model up front because you can’t see what’s coming down the road in two, three, or five years. The late-binding approach gives you maximum flexibility for using your data to tackle a wide variety of use cases as the needs arise and prevents you from wasting resources.
To be successful, the late-binding approach to data warehousing requires the right technology foundation. Organizations trying to implement a late-binding data warehouse with traditional ETL or data processing tools often find themselves overwhelmed with the volume of analytic requests. Their methodology scales, but their tools and people do not.
At the core of the Health Catalyst® Data Operating System (DOS™) platform is a metadata-driven data processing engine and toolset that allows organizations to scale their analytics efforts. It enables the building of a late-binding data warehouse with a significantly lower total cost of ownership than other solutions. Additionally, DOS allows you to take the analytic value contained in your data warehouse and use it in new and interesting ways to drive clinical and business improvements throughout your organization.
Would you like to use or share these concepts? Download this presentation highlighting the key main points.





