Many health systems are eager to embrace the capability of natural language processing (NLP) to access the vast patient insights recorded as unstructured text in clinical notes and records. Many healthcare data and analytics teams, however, aren’t experienced in or prepared for the unique challenges of working with text and, specifically, don’t have the knowledge to transform unstructured text into a usable format for NLP.
Data engineers can follow four need-to-know principles to meet and overcome the challenges of making unstructured text available for advanced NLP analysis:
1. Text is bigger and more complex.
2. Text comes from different data sources.
3. Text is stored in multiple areas.
4. Text user documentation patterns matter.
 Download
Download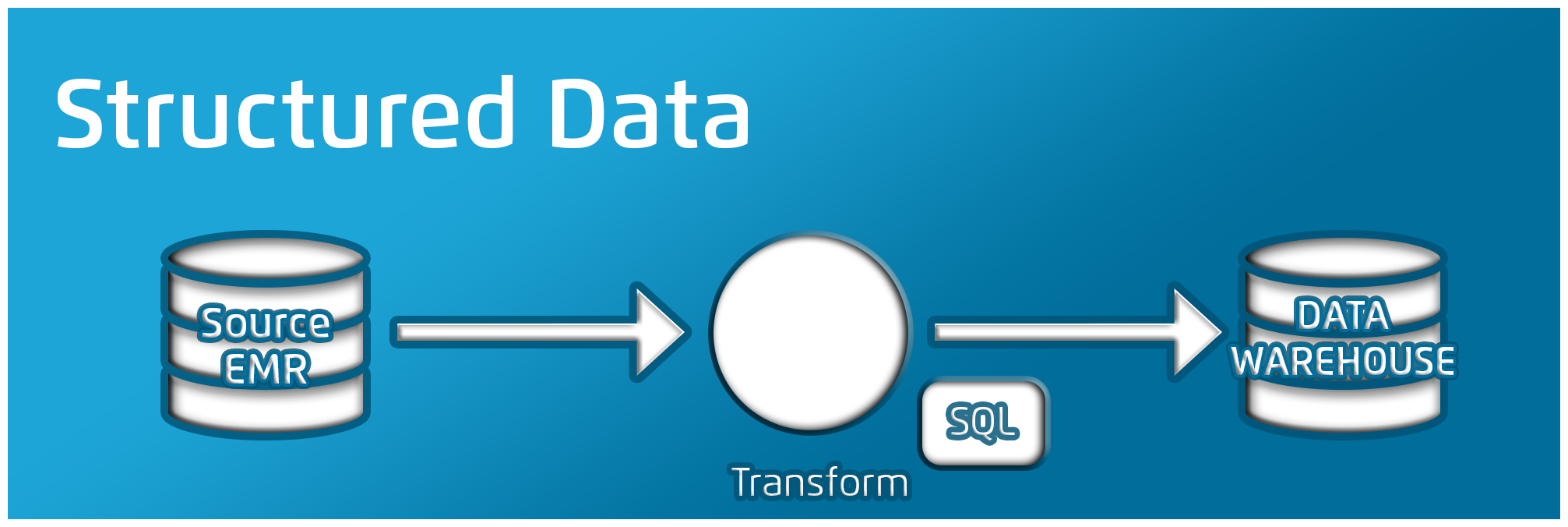
The healthcare industry has recently realized a sharp increase in interest in natural language processing (NLP). The unstructured clinical record contains a wealth of insight into patients that isn’t available in the structured record. Additionally, advances in data science and AI have introduced new techniques for analyzing text, broadening and deepening understanding of the patient. Any organization seeking to leverage their data to improve outcomes, reduce cost, and further medical research needs to consider the wealth of insight stored in text and how they will create value from that data using NLP.
The first step in using NLP can be the most difficult, and many organizations never meet the initial challenge of making the data available for analysis. NLP requires that data engineers transform unstructured text into a usable format (see need to know aspect #2 below) and in a location where the NLP technology can make use of it. This NLP pre-requisite can be a complex process, involving larger data sets and different technologies than many data engineers are familiar with.
This article outlines four need-to-know ways to meet and overcome the challenges of making unstructured text available for advanced NLP analysis. It’s focused on the challenges and skillsets required to build a solid foundation for text analytics.
In my role of leading NLP efforts for healthcare analytics vendor, I recently worked on a patient safety surveillance tool that helps health systems monitor for potential adverse events. For example, administering Narcan to reverse the effects of a patient who doesn’t respond well to a pain killer or hospital-acquired pressure ulcers. While the administration of Narcan is commonly documented in structured data, pressure ulcers are often found in unstructured nursing notes.
To get the necessary data to improve patient safety, we needed to leverage the free text of nursing notes. We found that five of the 33 adverse events were primarily documented in unstructured text. To access and leverage the text data in the patient safety tool, we needed NLP. We needed more, however, than the right tools for NLP itself to use the rich information unstructured text holds.
To effectively build a data pipeline for text, and navigate unfamiliar challenges, data engineers must understand four key points:
An average EMR record—such as a medication, allergy, or diagnosis, etc.—runs between 50 to 150 bytes, or 50 to 150 MB per million records. On the other hand, the average clinical note record is approximately 150 times as large. With large health systems storing hundreds of millions of note records, this scale introduces data transfer and storage complexities that many data engineers won’t have previously confronted.
Experienced data professionals know well that data sources vary widely. The data model for one vendor is different from another (e.g., from one EMR to another). With text, the stakes are even higher. A typical data pipeline for structured data (Figure 1) from an EMR is less complex than an unstructured data pipeline.
Structured data typically involves working with just SQL and supporting tools (e.g., SSIS or Informatica). On the other hand, working with unstructured text (Figure 2) involves a variety of tools outside the typical data engineer’s skillset—including programming languages such as C# or Python and search engines such as Elasticsearch and SOLR. On top of this, the transformations required for text vary significantly based on how it’s stored in the source.
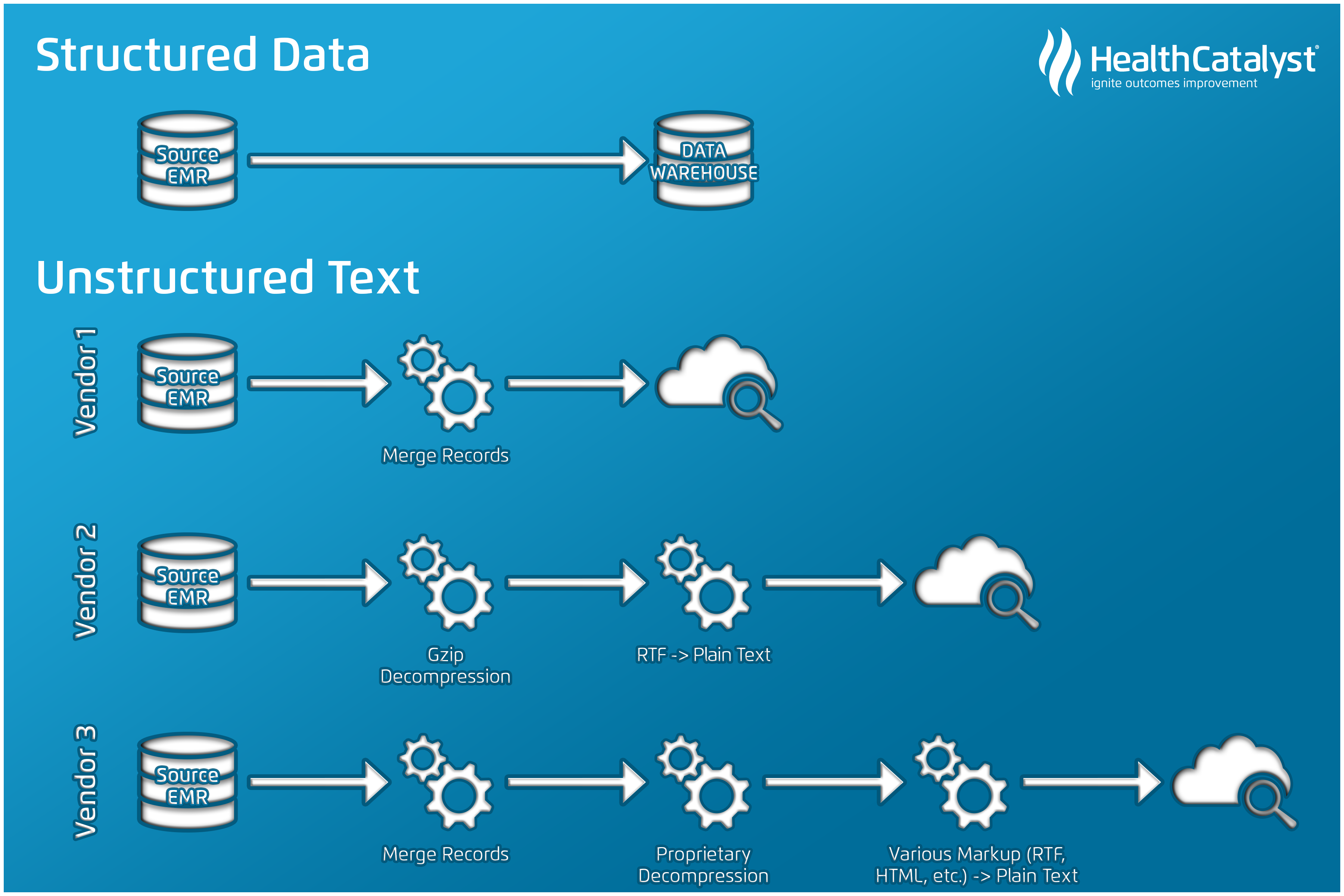
It’s easy to think of text as a monolith—that all the text in a system lives in one place. Where text is stored, however, depends on the type of text and the system in use. For example, clinical notes, radiology reports, and pathology reports may exist in two or three different sets of tables, depending on the source system. Location will also vary based on the specific implementation of that system. With one vendor’s system, radiology reports may be in the same table as clinical notes or in the same tables as results, depending on the workflow decisions behind the configuration of the organization’s EMR.
A report’s text source can also influence its location. One large EMR vendor stores shorter text results as a separate table from notes and reports, while another vendor will put results from the tasking/messaging engine in another table. Engineers need to validate the specific data needed for the current NLP use cases (e.g., in-hospital falls data) and focus first on bringing in that data. If they need additional data, they can expand from there.
Understanding how users document data matters. For example, during a recent project to identify adverse events for patients, we searched for documentation of in-hospital falls. The patient safety expert I was working with, a nurse, had always seen patient falls documented in nursing progress notes, but we found very few mentions of any falls in those notes. After discussions with the health information management group and nurses at the health system, we learned that it used a structured-only documentation methodology for nursing, and the best source for documentation of in-hospital falls would be the physician progress notes.
This insight made a small difference in how our data scientist searched for falls data, but it made a significant difference in the results. Filtering which notes went into the NLP algorithm improved accuracy, particularly the sensitivity of the algorithm.
Working with text data is different than structured data. Keep in mind this article’s four lessons: unstructured text records are significantly larger that structured records; data engineers often need to preprocess text before running NLP, which often requires tools outside normal data pipelines; text may be stored in different areas of source systems or EMRs; each organization may document text differently.
Data engineers who want to meet the challenges of text and unlock its rich information will benefit by starting on a focused project, rather than taking on too many text tasks at once (a bottom-up versus a top-down approach). I recommend starting with a great use case that aligns with organizational goals. Using the patient safety scenario from earlier, if an organization is focused on improving patient safety, it may find that safety events are documented in unstructured text, limiting its ability to identify patient harm. Starting by pulling text for one type of safety event (e.g., deep vein thromboses) can help data engineers form a process. They can then replicate this process for other use cases and start pulling the text data and using NLP tools to reduce patient harm and transform healthcare more broadly.
Would you like to learn more about this topic? Here are some articles we suggest:
Would you like to use or share these concepts? Download this presentation highlighting the key main points.




